Пишем автотесты для UI на базе Selenide. Часть 1
Поздравляем с наступающим Новым 2022 годом всех бесстрашных ручных тестировщиков, которые ищут пути развития своей карьеры и хотят приобрести навыки в автоматизированном тестировании.
Эта статья — продолжение серии материалов о переходе мануального тестировщика в автотестеры. Статья будет условно поделена на теоретическую и практическую часть. Разберем особенности UI-тестирования и напишем автотесты с помощью инструмента Selenide.
Другие статьи можно найти по тэгу #автоматизация
UI-тестирование. Немного теории
UI-тестирование — это этап в процессе тестирования ПО, проверяющий интерфейс. Тестирование интерфейса помогает нам проверить функции приложения, имитируя действия пользователей, т.е. в процессе тестирования выполняется проверка элементов, проверка на их корректность с помощью ввода данных в приложение через устройства ввода или средств автоматизированного UI-тестирования. Это можно делать руками или с помощью автоматизации.
В иерархии UI-тестирование находится на вершине пирамида Майкла Коэна, то есть для него требуется наименьшее количество тест-кейсов.
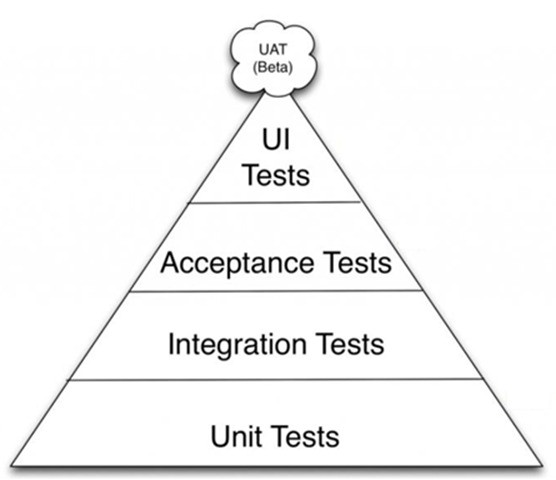
Что следует знать о UI-тестировании:
-
Написание и выполнение UI-тестов занимает больше времени, чем Unit или API тесты, поэтому их количество меньше т.к. отклик от системы получаем позже, чем могли при другом виде тестирования. Во время управления методики разработки Agile скорость релизов растет, что требует от нас покрывать UI-тестами основную бизнес-функциональность, которую мы не можем проверить иначе.
-
Проверка usability — проверка интерфейса на удобство использования, чтобы он был несложным и интуитивно понятным для пользователя (легко понимаем), был привлекательным;
-
Проверка согласованности данных при взаимодействии с интерфейсом ПО;
-
Проверка функциональности логики, заложенной в UI.
Стратегии UI тестирования в данной статье не будут описаны, данную информацию можно найти в других источниках.
Описание локаторов для автоматизированного тестирования
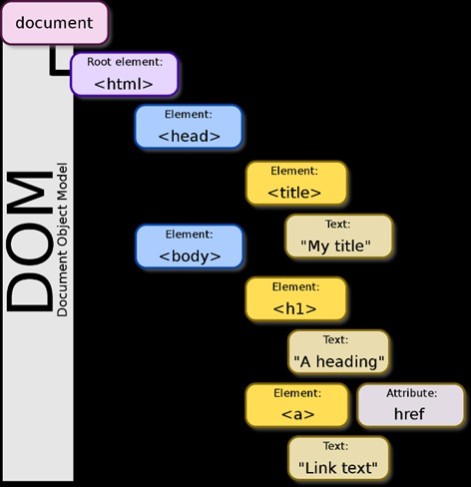
Есть разные типы локаторов, которые помогают найти элемент на странице, самыми популярные это XPath и CSS (локатор=селектор). Посмотреть локаторы мы можете в режиме разработчика во вкладке элементы.
Пример:
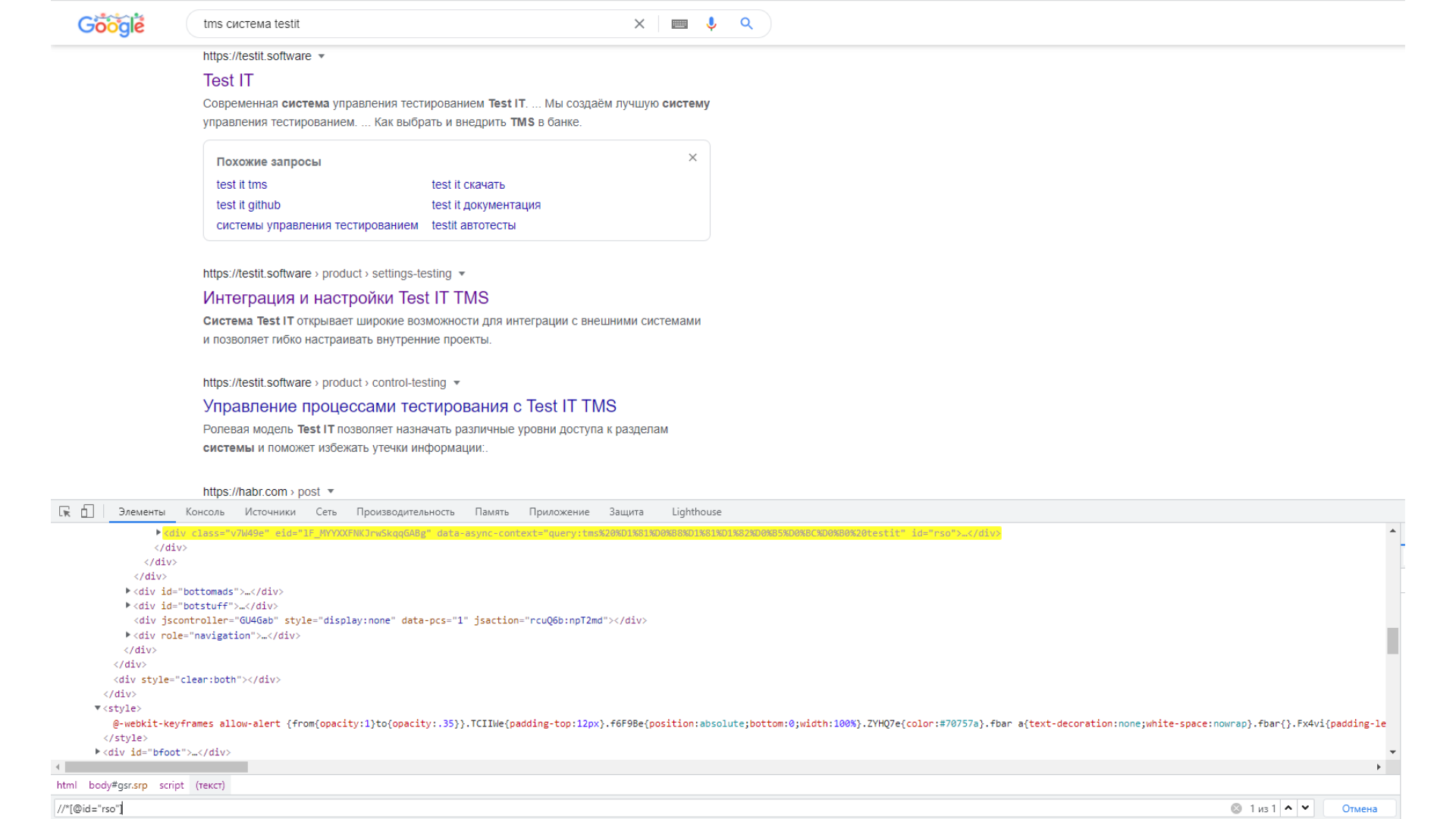
Xpath: //*[@id="rso"]/div[1]/div/div[1]/div/div/div/div[1]/a/div/cite
CSS: #rso > div:nth-child(1) > div > div:nth-child(1) > div > div > div > div.yuRUbf > a > div > cite
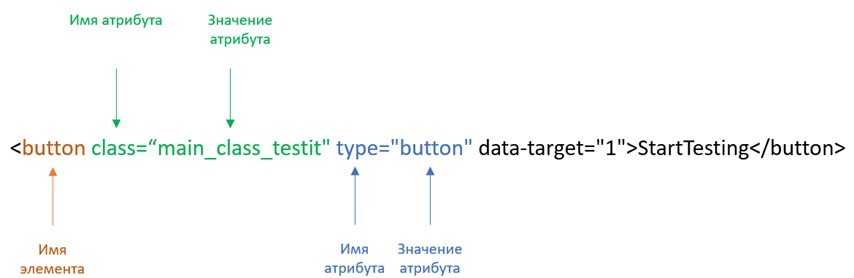
Первая мысль, которая могла появиться у вас: "Ага, всё понятно, сейчас посмотрю, как использовать локаторы в Selenide, и буду автоматизировать свои кейсы”. Спешу огорчить, такие локаторы могут легко измениться при изменении верстки. В результате выполнения теста в будущем можем легко получить fail тест, т.к. не будет найден элемент. Если поддерживать локаторы элементов таким образом — будет уходить много времени для поддержки актуальных локаторов элементов в тестах вместо развития тестового модуля.
Вывод 1: требуется составлять локаторы, которые будут стабильны к изменениям верстки. В результате будет затрачиваться меньше времени для поддержки их работоспособности и актуализацию.
Вывод 2: при построении локаторов требуется строить их с учетом уникальности, т.е. в результате поиска на выходе должны иметь единственное совпадение. Таким образом, будет выполнено взаимодействие с ожидаемым элементом, а не с первым совпадением, который будет найден.
Давайте более подробно остановимся на локаторах CSS и Xpath и опишем селекторы на примере старенького новогоднего сайта «Северный полюс».
Xpath
Xpath — это язык запросов к элементам xml документа. C xml вы часто взаимодействуете при обмене данными. В плане UI автоматизации тестировщики, как правило, работают с xml в формате html документа для обращения к разным типам элементов. Например: поле ввода данных, кнопка, ссылка (html — язык разметки страницы). Описание по тегам html можете почитать на сайте. По xpath локаторам мы двигаемся по DOM-модели (набор html тегов). Обязательно познакомьтесь с осями xpath — это база языка XPath.
Попробуем на практике на сайте http://www.northpole.com/. Откройте браузер разработчика (F12), в моем примере это Google Chrome, далее откройте вкладку с элементами (Elements), дополнительно можете открыть окно консоли. Для ввода локатора xpath требуется выбрать любой элемент в поле с атрибутами и нажать Ctrl+F.
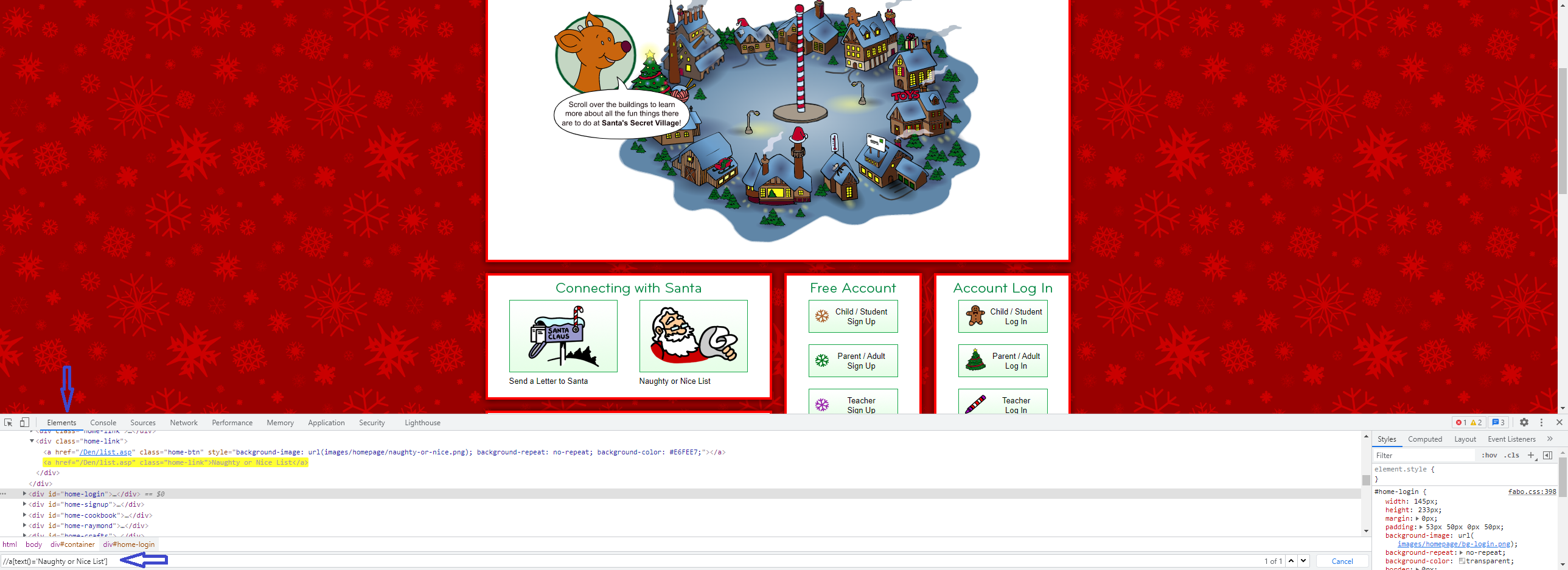
Особенностью xpath является начало селектора с / или //, что означает:
- / — переход поочередно по элементам
- // — возврат всех элементов по совпадению
Давайте продублируем локаторы выше, но с помощью XPath-локаторов:
1). После перехода на базовую страницу нам требуется проверить отображение класса — class='untilmerry'. Для этого попробуем найти атрибут класса и его значение:
- поиск по имени элемента и атрибуту с проверкой с заданным значением: //img[@class='untilmerry']
2). Далее попробуем найти кнопку “Naughty or Nice List” разными способами с помощью xpath:
1 способ: поиск по абсолютному совпадению текста названия кнопки:
//a[text()='Naughty or Nice List']
2 способ: поиск по частичному совпадению текста названия кнопки:
//a[contains(text(),'ghty or Nice')]
Примечание: для частичного поиска текста используется конструкция contains(text(),’[тескт_поиска]’) или по значению внутри атрибута contains(@class,'[тескт_поиска]')
3 способ: поиск кнопки по атрибуту href и класса на одном уровне:
//a[@href='/Den/list.asp'] [@class='home-btn']
Примечание: данный способ поиска элементов необходим в случае неопределенности элемента по какому атрибуту. В данном случае есть 2 элемента с одинаковой ссылкой href, но разным классом.
3). Далее в случае перехода по кнопке у нас будет таблица с radio button. Попробуем найти ее по частичному совпадению значения атрибута id:
Поиск таблицы с radio button по частичному совпадению значения атрибута
“id” - //form[contains(@id,'uest')]
4). Найдем атрибут заголовка страницы по имени элемента, атрибуту и его значению:
Поиск элемента div с атрибутом id со значением:
//div[@id='top']
Примечание: id проставляются на важные узлы и на элементы с которыми часто взаимодействуете, а также они могут быть динамическими.
5). При переходе по кнопке «Naughty or Nice List» в таблице имеется структура с несколькими элементами. Попробуем найти совпадение в таблице элемента с id='questions' по букве «i»:
//form[@id='questions']/ul[1]//li[contains(text(),'i')]
где //form[@id='questions']/ul[1] – переход к элементу ul c индексом 1,
//li[contains(text(),'i')] — поиск всех элементов li с совпадением по букве «i». Примечание в коде Selenide будет выполнена немного отличный способ поиска локатора для лаконичности кода.
6). Выполним поиск по @id='questions' и выполним переход к его родителю:
//form[@id='questions']/..
CSS
CSS — это язык на котором задаются стили на странице. С помощью css селекторов локатор имеет уникальный набор атрибутов элемента для его поиска. Есть разные виды css селекторов с которыми можно познакомиться тут. CSS локатор можно проверить в консоли браузера в инструменте разработки (f12) в разделе Console.
$ (): Один знак доллара используется для поиска одного веб-элемента;
$$ (): двойной знак доллара, используемый для поиска нескольких веб-элементов.
Давайте продублируем локаторы выше, но уже с помощью CSS-локаторов:
1). Поиск заголовка тестируемого сайта:
Поиск по имени элемента и атрибуту с проверкой с заданным значением: img[class='untilmerry']
2). Далее попробуем найти кнопку «Naughty or Nice List» разными способами с помощью xpath:
1 способ: поиск по абсолютному совпадению текста названия кнопки
a[href='/Den/list.asp'][class='home-link']
2 способ: поиск по частичному совпадению текста названия кнопки (*):
a[href='/Den/list.asp'][class*='-l']
Примечание: для частичного поиска значения атрибута можно выполнять поиск по общему совпадению(*) - a[href='/Den/list.asp'][class*='me-li']
по совпадению с начала строки (^)
a[href='/Den/list.asp'][class^='home-']
по совпадению с конца строки ($)
a[href='/Den/list.asp'][class$='link']
3 способ: поиск кнопки по атрибутам href и class на одном уровне:
a[href='/Den/list.asp'][class='home-btn']
Примечание: Данный способ поиска элементов необходим в случае неопределенности элемента по какому либо атрибуту. В данном случае есть 2 элемента с одинаковой ссылкой href, но с разным классом.
3). Далее в случае перехода у нас будет таблица с radio button. Попробуем найти ее по частичному совпадению значения атрибута id:
Поиск таблицы с radio button по частичному совпадению значения атрибута «id» — form[id*='uest']
4). Найдем атрибут заголовка страницы по имени элемента, атрибуту и его значению:
Поиск элемента div с атрибутом id со значением:
div[id='top'] или другой вид записи #top (поиск по всех элементах где есть id = top).
5). При переходе по кнопке «Naughty or Nice List» в таблице имеется структура с несколькими элементами. Выберем первый элемент ul у атрибута id = questions, далее отфильтруем значение c «i» с помощью Selenide:
#questions > ul:nth-child(1) > li > input
где #questions > ul:nth-child(1) — переход к элементу ul c индексом 1,
> li > input — поиск всех элементов li c элементом input.
Примечание: в коде Selenide будет выполнен немного отличный способ поиска локатора для лаконичности кода, а также будет наложен фильтр для поиска элементов с буквой «i».
Примечание: символ «>» отображает прямую зависимость поиска между родителем и ребенком, но можно выполнить поиск без него. Таким образом будет выполняться поиск элемента во всей вложенной структуре элементов. Например, в примере выше можно исключить элемент li: #questions > ul:nth-child(1) input
Продолжение с практической частью на Selenide выйдет на январских каникулах в 2022 году :)
