Как в Test IT построили конвейер качества: от кода до прода за 8 шагов

Обычно QA зовут в самом конце, когда фича уже готова: «Вот тебе, проверь побыстрее». Начинается гонка за багами, стрессы, кто кого перекричит. Но можно иначе: выстроить процесс так, чтобы фича шла к пользователю без боли и у тестировщиков оставалось время на вдумчивую работу.
SDET-инженер Test IT Андрей Черных рассказывает, как команда прошла путь от «ой, баг на проде» до поэтапного пайплайна на примере одной простой фичи. Эта статья — не про абстрактные подходы, а про настоящий опыт команды, как одну пользовательскую хотелку превратили в отлаженный, повторяемый и спокойный процесс.
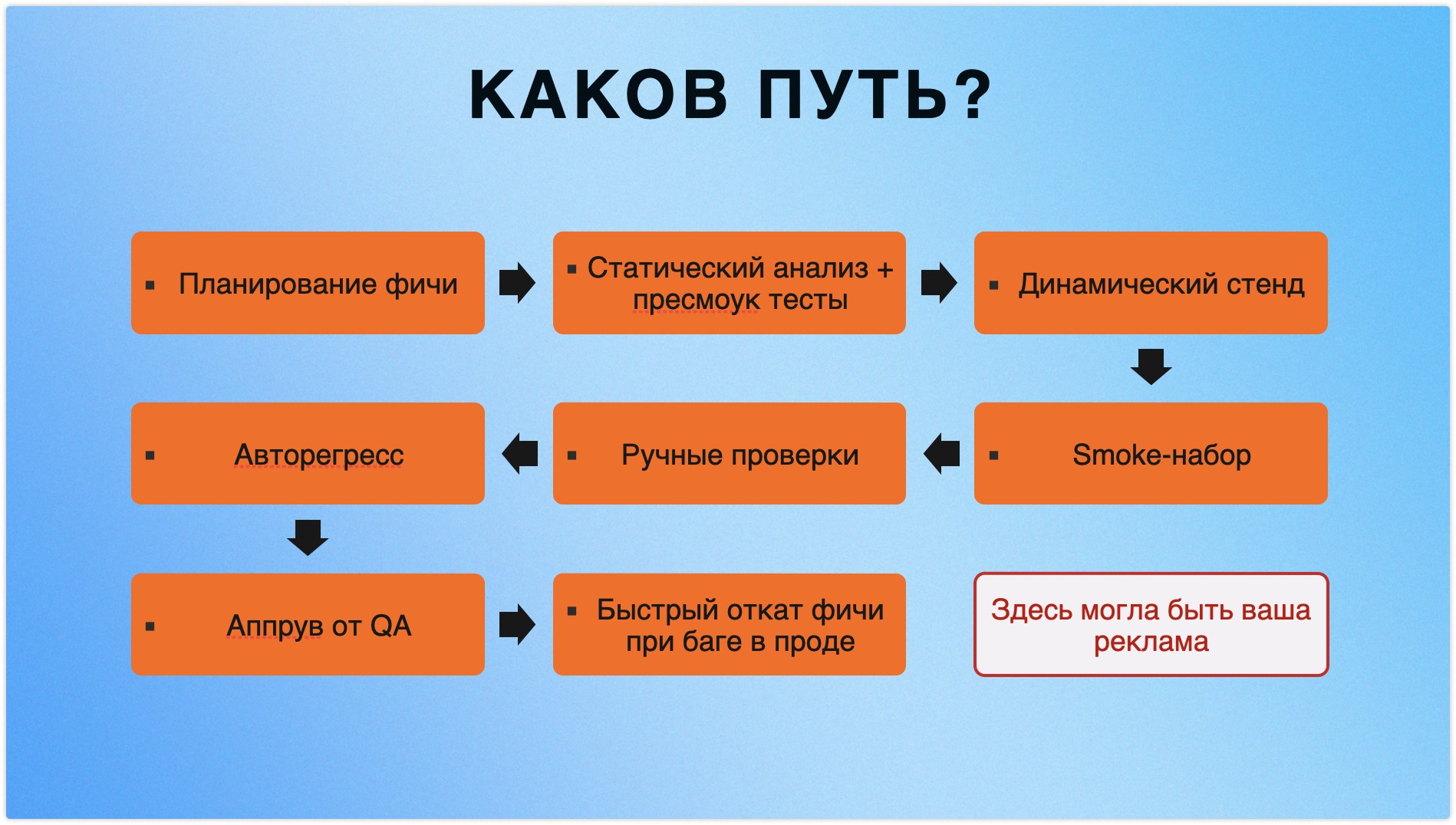
Шаг 1. Планирование
Фича была простая: сделать возможность создавать ручные тест-кейсы не только через тест-план, а напрямую из библиотеки или секций, чтобы уменьшить количество кликов для создания тест-плана. Запрос пришел от пользователей.
❓ Казалось бы, что тут думать: но мы включили QA сразу и обнаружили 8 (!) проблем: от UX-мелочей до нюансов с тарифами и ролями.
❓Как мы это поняли: просто задали вопросы еще до того, как кто-то начал писать код.
Наш QA-специалист прошелся по требованиям и макетам, и возник целый ряд уточнений. Это позволило нам не просто избежать переделок, а сразу сделать фичу понятнее для конечного пользователя. В итоге оформили отдельную задачу, доработали спецификацию и сэкономили время всей команде.
Для хранения документации мы в Test IT используем систему управления проектами TeamStorm, туда же отправляются реквесты от пользователей.
На основе этой спецификации формируются задачи. Тут же подключается QA и начинает тестировать требования. Ряд вопросов, которые возникли при уточнении требований:

И получилась еще одна задача:

Шаг 2. Генерация тестов с помощью ИИ
На этом этапе хочется облегчить жизнь тестировщикам. Мы настроили интеграцию между TeamStorm и Test IT, прикрутили GigaChat. Прямо из задачи можно сгенерировать тесты по требованиям. В Test IT доступна ИИ-интеграция с GigaChat и YandexGPT.
? Подробнее о том, как работает эта фича и как подключить интеграцию — в инструкции от менеджера по продукту Test IT Анастасии Николаевой
У нас получилось 10 кейсов — не идеальные, но уже хороший старт. Все равно причесываем вручную, потому что у них не всегда есть нужный контекст, нет привязки к системе ролей, не хватает специфики по данным.
Например, если в задаче есть нюансы с правами доступа или разные сценарии для тарифов, модель может их не учесть. Но для черновика это отличная точка опоры. Главное, что нужно помнить: ИИ помогает, но не заменяет. Он экономит время на рутине, но не снимает ответственности за качество.
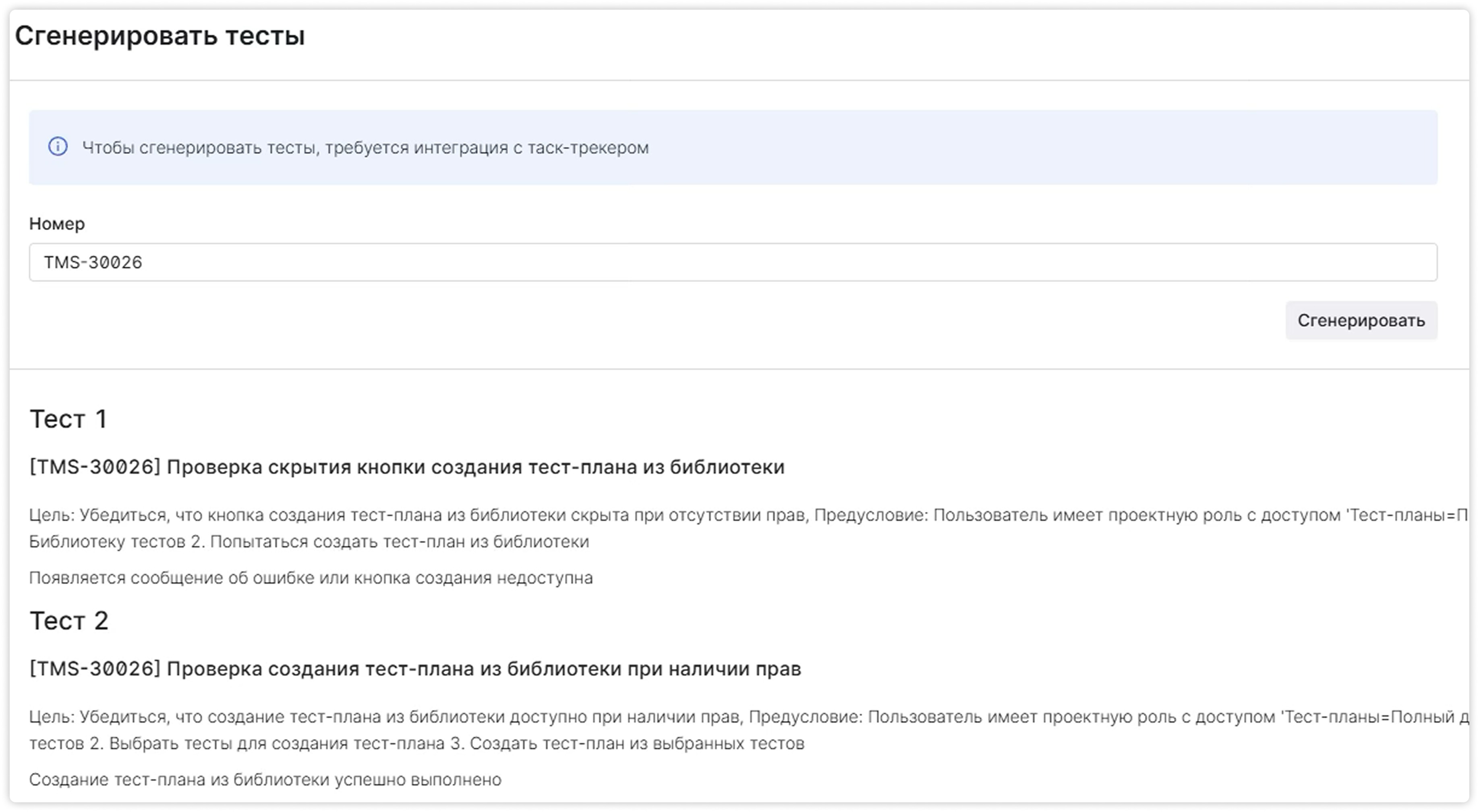
? Попробовать эту возможность можно прямо сейчас в облаке. ИИ-генерация доступна для всех тарифов
Шаг 3. Фича-флаги через Growthbook
Под фичу сразу создается фича-флаг — чтобы потом не было мучительно больно. Мы ведем их в Growthbook — нашей in-house системе, по сути аналог LaunchDarkly или Unleash. Она позволяет гибко управлять включением функциональности: по ролям, по тарифам, по проценту пользователей.
Зачем он нужен? Чтобы:
-
Выключить фичу одним тумблером, если что-то пойдет не так.
-
Делать канареечный релиз: сначала на малую долю пользователей.
-
Включать разную функциональность на разных тарифах (например, дать ручное создание кейсов только на платных планах).
Флаг настраивается заранее: разработка знает, что за ним будет стоять логика показа. QA — что функциональность можно отключить в любой момент. Бизнес — что можно провести A/B-тест и посмотреть реакцию. Если бы мы это не сделали, баг бы выкатился в прод. А так мы его просто выключили и пошли спокойно чинить.
Фича-флаг в Growthbook:

А вот он в коде:
Шаг 4. Пресмоук-тесты и статический анализ
Разработчик коммитит, а QA уже на подстраховке. У нас настроено сразу несколько уровней защиты:
-
CommitLint проверяет формат коммитов. У нас заведен шаблон, и если разработчик пишет просто «фикс багов», джоба валится: «Тип не указан, описание не по формату».
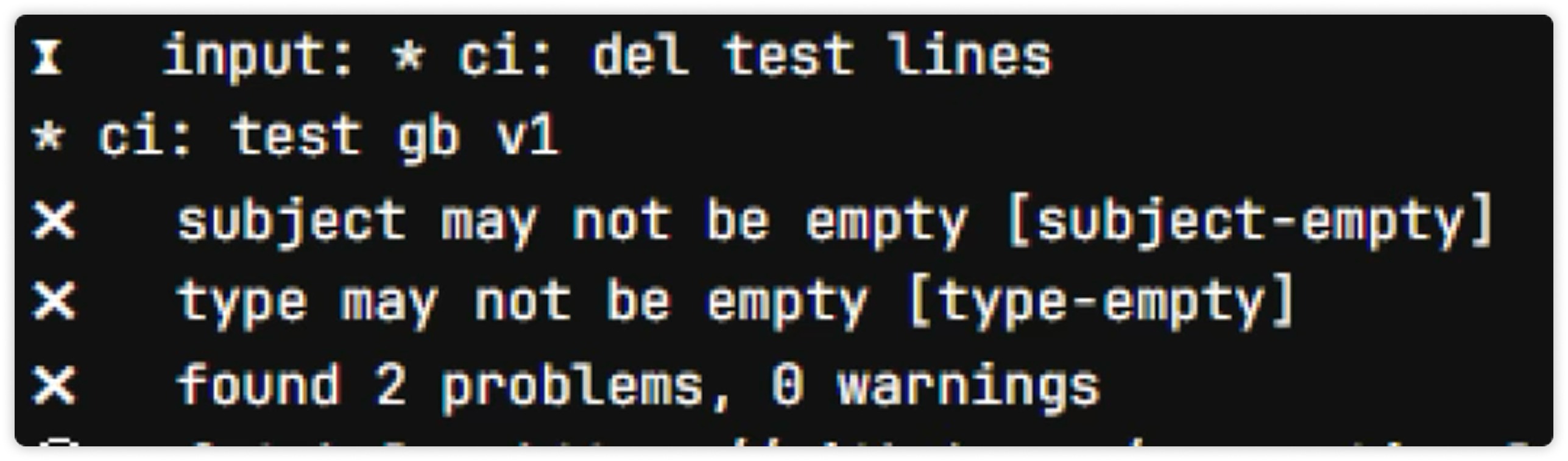
- Secret Detection проверяет, чтобы в git не уехали токены, пароли, ключи. Такое бывает, особенно в спешке.
- Symgrep ищет уязвимости по кастомным правилам. Например, SQL-инъекции, XSS, опасные регулярки.
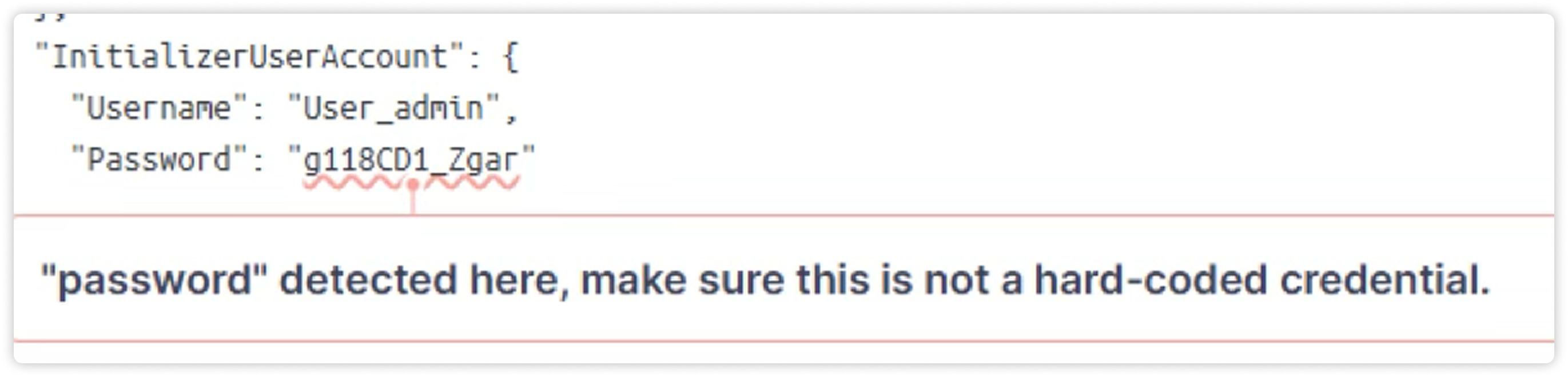
- SonarQube дает фидбэк по потенциальным архитектурным проблемам и безопасности. Например, если в коде прямым текстом лежит password = "admin" — подсветит. И об узких местах в коде предупредит.
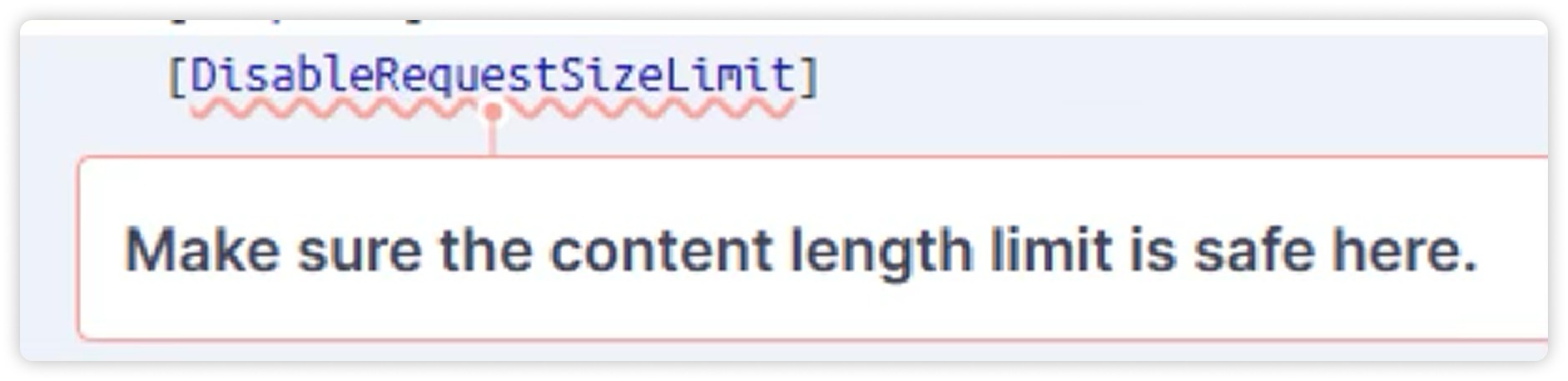
Плюс юнит-тесты, API-тесты, интеграционные. Все это запускается до того, как фича доходит до QA. Если что-то ломается, пайплайн останавливается, и фича дальше не идет.
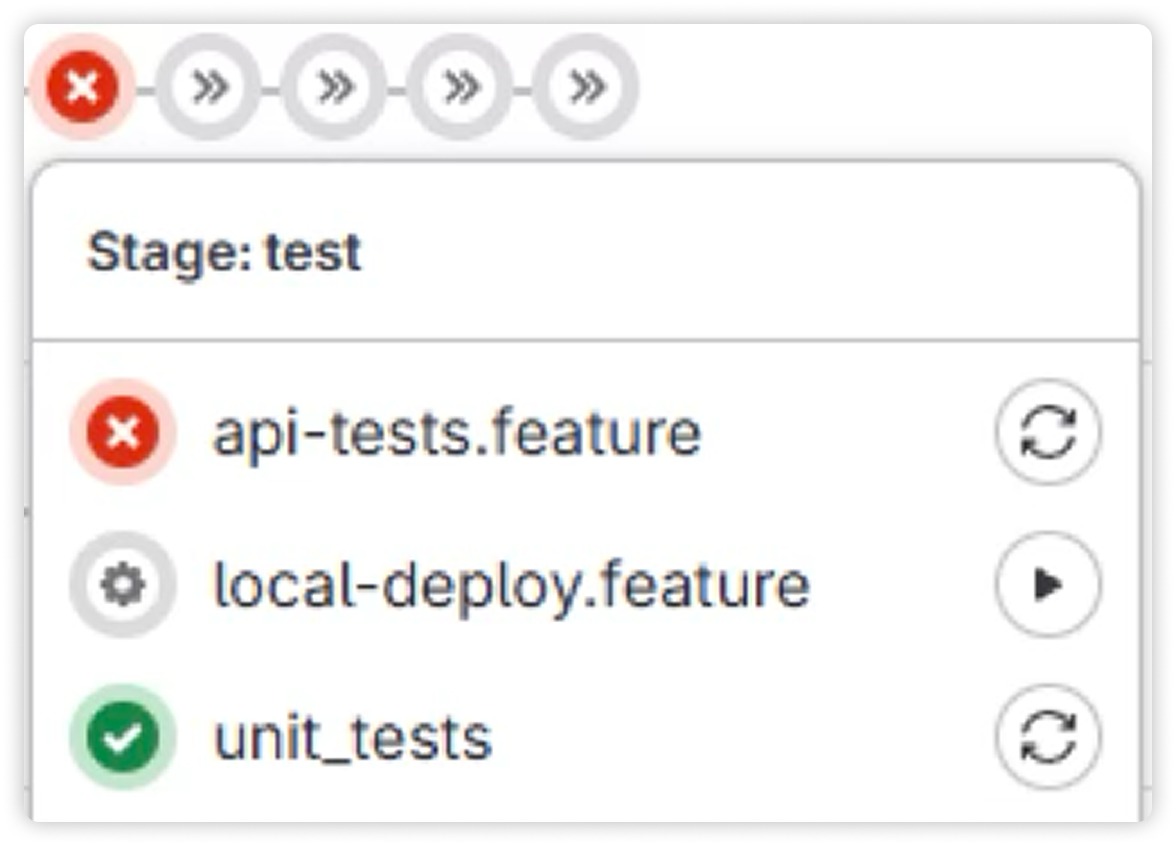 |
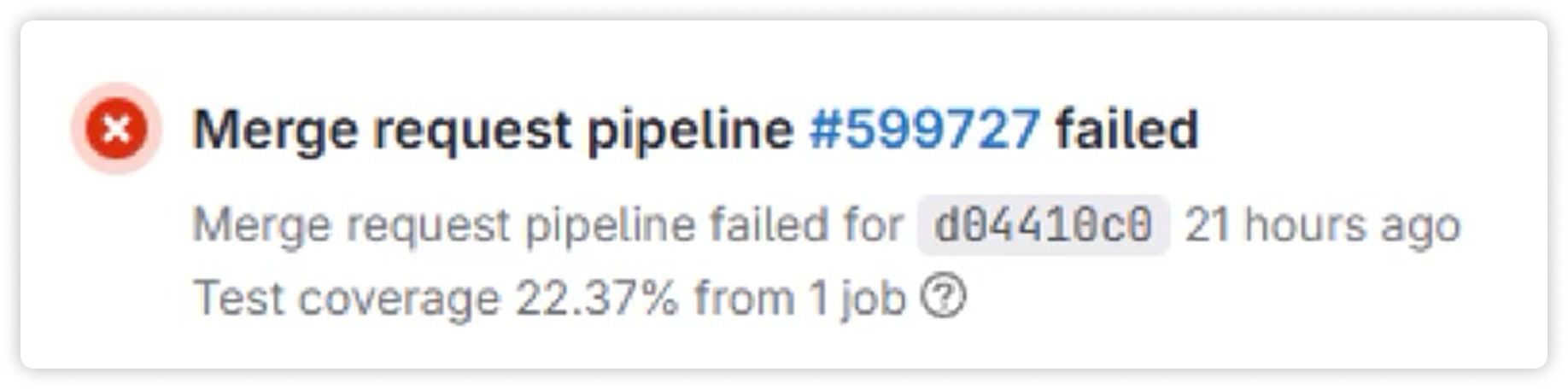 |
 |
Зачем нам все это?
-
Во-первых, это и есть статический анализ — инструменты, которые прогоняют код без его запуска. Это дешевле и быстрее, чем ручная проверка, и позволяет сразу ловить очевидные ошибки.
-
Во-вторых, это защита и экономия: QA не тратит время на то, что можно отловить автоматически, а разработчик получает фидбэк, пока не забыл, что он вообще там написал.
Шаг 5. Динамический стенд и смоуки
На каждый MR автоматически поднимается отдельный стенд в Kubernetes. Адрес, окружение, фича-флаги — всё свое. Это решает много проблем: никто не борется за общий стейдж, ничего не простаивает, стенды не конфликтуют между собой. Раньше мы использовали статические стенды, и когда несколько фич пытались развернуться на одном, начинался хаос: то ветка не та, то стенд не очищен, то кто-то заливает заново. Теперь каждая фича живет в своем изолированном окружении.

На стенде запускается смоук-набор, около 50 тестов. Это базовая проверка: если эти тесты падают, MR дальше не идет. Мы специально держим набор компактным, чтобы проверка шла быстро. Если смоук проходит, можно двигаться дальше.
Работает это все на Сallisto — это распределённый раннер, надстройка над Kubernetes. Как альтернатива Selenium Grid, только с API, автоматическим масштабированием и возможностью управлять браузерами как подами. Быстро, гибко, удобно. Но, как мы любим повторять в команде: «Не завязывайтесь на Сallisto, подход важнее инструмента».
Шаг 6. Ручное тестирование и автоматизация
Теперь подключается QA. После того как прошли смоуки и разработчик выкатил стабильный билд, тестировщик заходит на стенд и начинает ручную проверку. Используем тест-план, который составлен заранее: туда входят и сгенерированные ИИ-кейсы, и уже знакомые нам сценарии.

Мы проходим тест-кейсы вручную, параллельно запускаем E2E на том же динамическом стенде. Пишем интеграционные и API-тесты для happy path, это помогает автоматизировать рутину и сэкономить время. Чек-листы трансформируются в полноценные кейсы, которые живут в Test IT.
Кроме того, у нас настроены Slack-уведомления: как только задача переходит в статус «готова к автоматизации», сценарии автоматически подтягиваются в Test IT, а платформа по вебхуку создает задачу в TeamStorm. Ее подхватывает дежурный автоматизатор и, если это API, пишет тест прямо в ветке разработки, рядом с кодом.
Такой процесс позволяет быстро закрывать критичные пробелы и развивать автопокрытие там, где оно действительно нужно.
Шаг 7. Регресс и найтраны
У нас есть ночной прогон на main — это наш золотой эталон. Он каждый день показывает, в каком состоянии находится продукт, даже если никто из команды активно ничего не делает. Это особенно важно, когда вливаются несколько фичей подряд и нужно понимать, какая из них могла повлиять на стабильность.
Когда фича готова, разворачиваем для нее дополнительный стенд и запускаем на нем регрессионный прогон — такой же, как ночной. Сравниваем результаты: если по сравнению с эталоном появилось что-то новое, разбираемся, это регресс или особенность конкретной фичи.
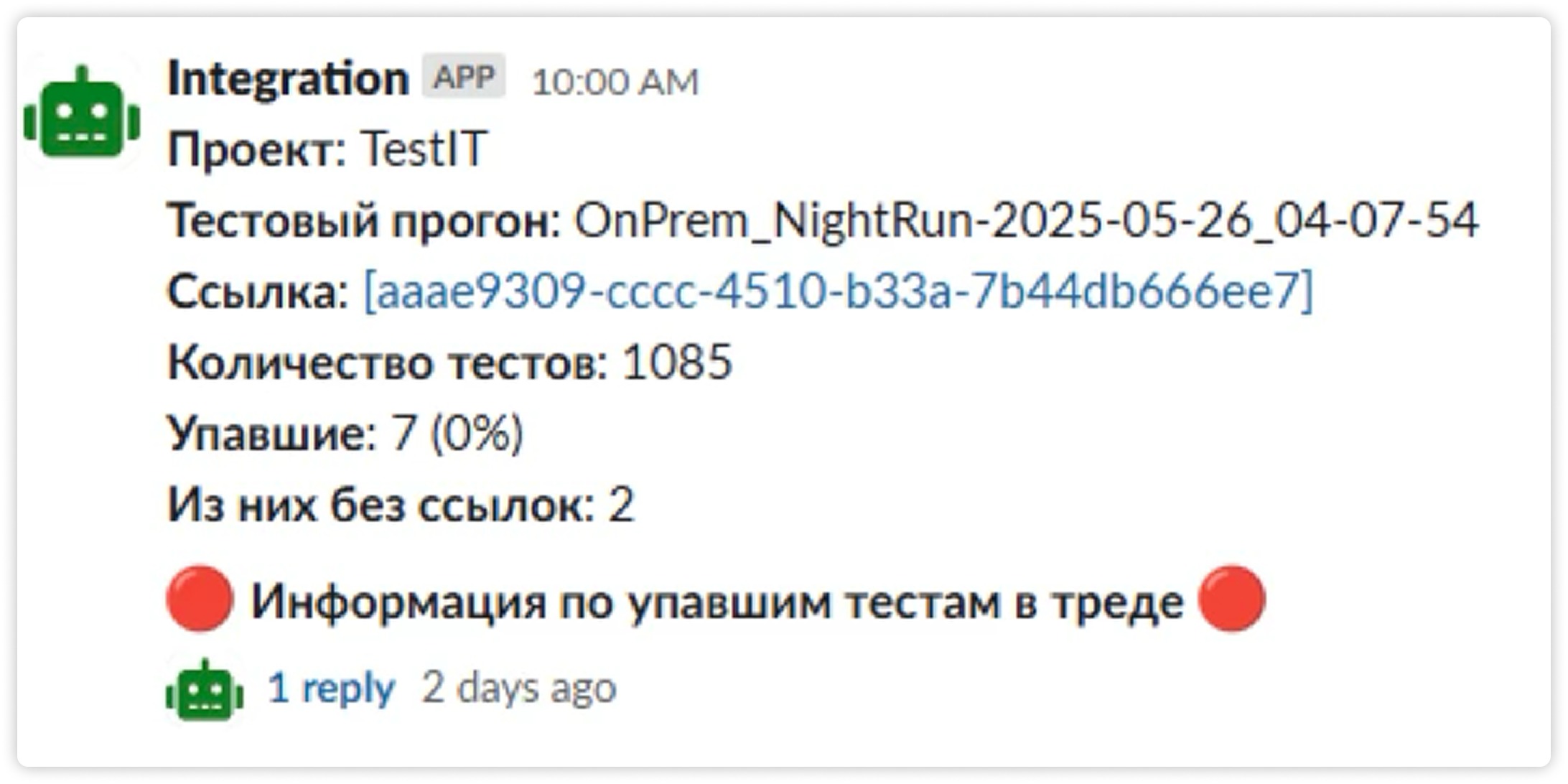
На нашей фиче так и произошло: один баг всплыл. Мы его быстро исправили и повторно прогнали тесты, чтобы убедиться, что он больше не воспроизводится. Такой подход помогает не гадать, стало хуже или лучше, а принимать решение на основе фактов: вливаем или чиним дальше.
Шаг 8. Финальный апрув от QA

Финальный стоп перед мержем — это не формальность, а еще один фильтр, когда QA собирает в одну картину все, что происходило по фиче:
-
Что показали тесты в Test IT
-
Прошел ли смоук, не упал ли nightly
-
Что подсветил SonarQube
-
Что вообще прилетело в CI по артефактам и логам
Если все ок, даем апрув и заливаем в main. Но бывает, что на этом этапе начинается давление: «Ну давай быстрее, нам надо в релиз». Тут важно не поддаться, а объяснить, что этот шаг защищает не QA, а всю команду.
Если отчетности мало или процесс не отлажен, QA действительно становится узким горлышком. Но когда есть прозрачность, этот апрув превращается не в тормоз, а в уверенность, что фичу можно выпускать.
Если баг на проде
Фича мгновенно отключается для пользователей. Продукт возвращается в стабильное состояние без выкатывания хотфикса. Это особенно важно, когда баг критичный и каждый час на счету.
Мы спокойно разбираемся, что пошло не так, устраняем проблему и, когда все готово, включаем фичу обратно. Главное условие, чтобы фича не вносила необратимых изменений, например, не мигрировала базу. Если миграции были, откат потребует дополнительных шагов и контроля.
Что осталось за кадром
Не все практики уместились в основной рассказ, но они тоже важны и работают в фоне:
-
Статичные стенды. Мы не отказались от них полностью: используем для миграций, сценариев с историческими данными и воспроизведения багов, которые сложно повторить в чистом окружении.
-
Нагрузочные тесты. Прогоняются ночью вместе с регрессами. А ещё у нас есть ежемесячные срезы, которые показывают динамику по производительности. Если видим просадку — сразу заводим задачи в разработку.
-
Безопасность. У нас есть отдельные процессы по security-тестированию, в том числе проверка зависимостей и ручной аудит для чувствительных фичей. Это не входит в основной пайплайн, но запускается регулярно.
Что изменилось
-
С ноября 2024 багов на проде меньше
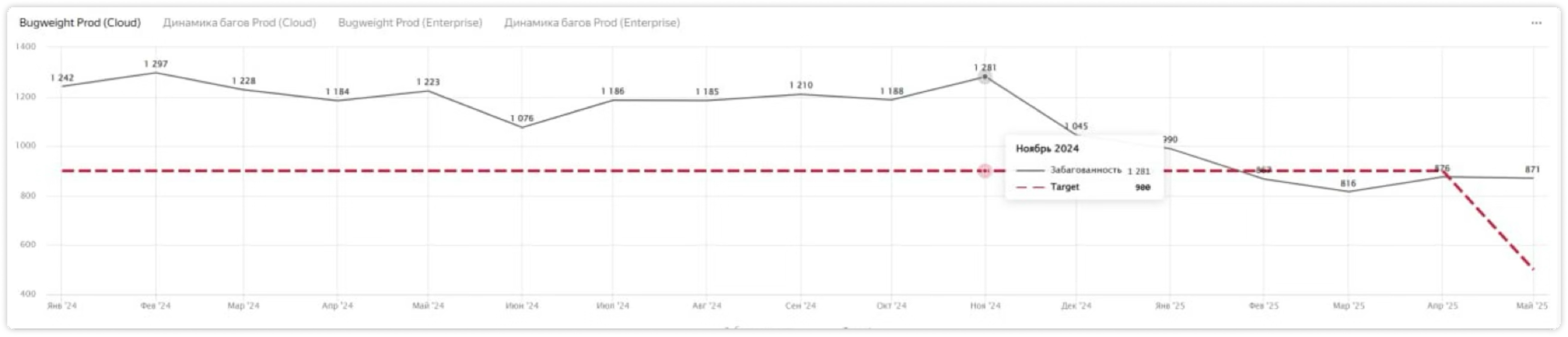
-
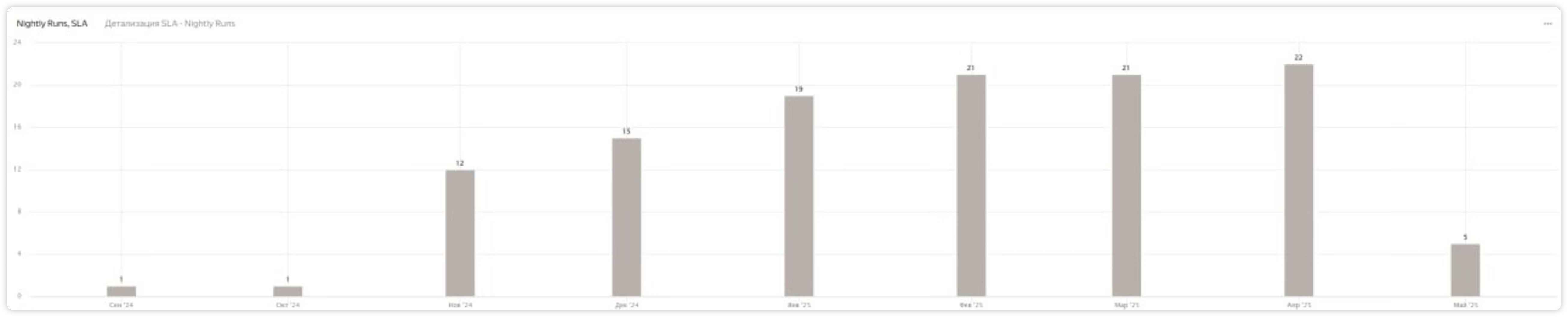
Баги ловим ночью, до релиза
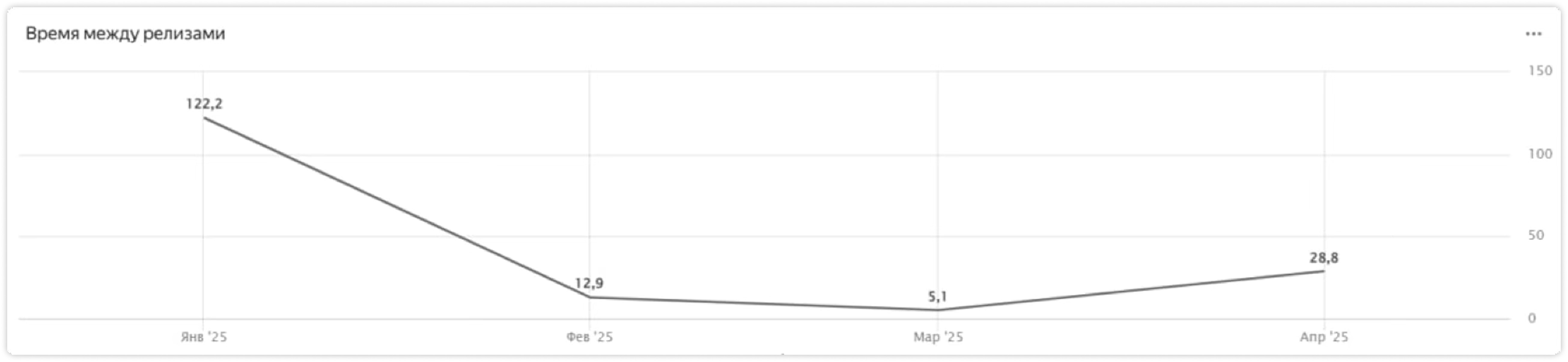
- Релизы стали быстрее и тише: cloud — до 6 часов, on-prem — чуть дольше
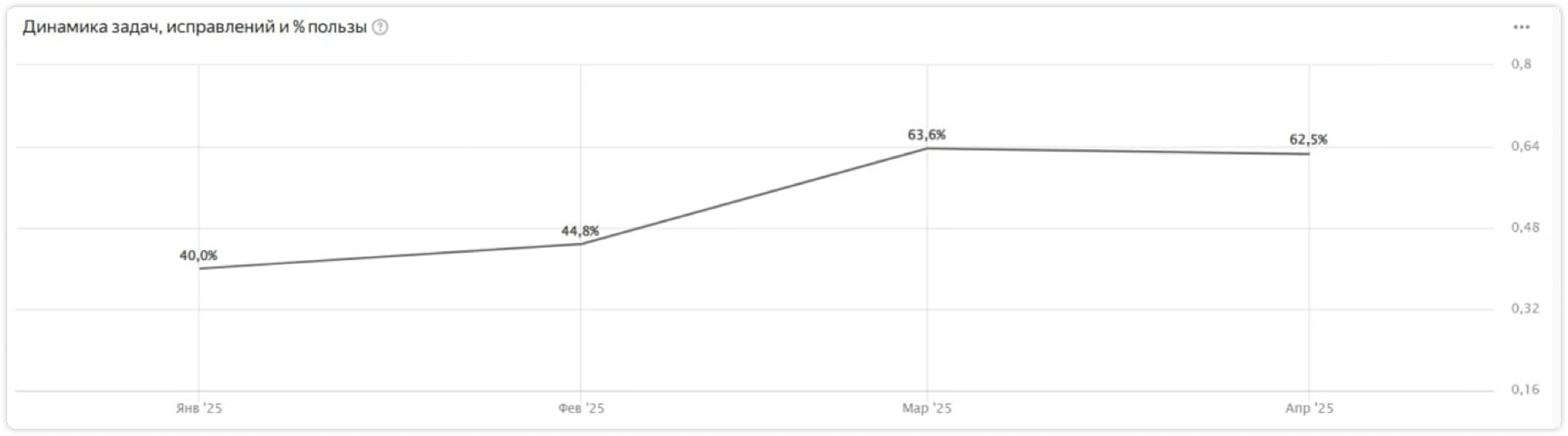
- Соотношение: теперь больше фичей, меньше багфиксов
С чего начать? Короткий гайд
Маленький шаг лучше, чем ничего. Выбирайте то, на что можете повлиять прямо сейчас, и двигайтесь оттуда.
✅ Подключите CommitLint. Это быстрый шаг — можно настроить за полдня. Поможет сразу убрать хаос в коммитах и добавит структуру в историю изменений.
✅ Договоритесь про юниты. Это самый дешевый способ ловить баги ещё до сборки. Главное — чтобы разработка действительно их писала.
✅ Начните с тест-анализа. Пройдитесь по требованиям до начала разработки. Даже один найденный баг на макете экономит часы (а иногда и дни) всей команде.
Не обязательно внедрять все восемь этапов сразу. Начните с того, на что реально можете повлиять, что проще всего подхватить и объяснить. Даже один элемент, например ночной прогон или CommitLint, уже заметно улучшает качество и экономит время команде. Мы тоже не пришли к идеальной схеме за один раз. Постепенно докручивали, смотрели, что срабатывает. Где-то отказывались, где-то пересобирали. И в какой-то момент вместо багов и беготни у тебя появляется стабильный и понятный процесс.
